1. 缓存与效果——结构优化
在 Transformer 解码器中,由于 token 的注意力依赖于前面的 token,因此,与其重新计算前面的上下文,不如缓存其 Key 和 Value。 这可以显著加速推理速度,但随着序列长度和模型维度的增长(dim 和 layers),可能会带来昂贵的内存开销。
在这种背景下,引入了多种注意力机制(为了尽可能支持更大的模型或者更长的序列,需要对 kv 进行压缩):
- Multi-Head Attention (MHA)
- Multi-Query Attention (MQA)
- Grouped-Query Attention (GQA)
- Multi-Head Latent Attention (MLA)
1.1. MHA
标准多头注意力(MHA)计算每个注意力头的 query、key 和 value 矩阵。


是第 个注意力头的输出。在推理过程中,所有 key 和 value 都会被缓存以加快推理速度。 但这种繁重的 KV 缓存是一个很大的瓶颈,会限制最大序列长度和批量大小。
1.2. MQA

为了缓解 MHA 中的 KV-cache 瓶颈,Shazeer 引入了 Multi-Query Attention (MQA),其中 key 和 value 在所有不同的注意力头之间共享。 这只需要非常轻量的 KV-cache,从而大大加快解码器推理速度。 然而,MQA 会导致质量下降和训练不稳定。 使用 MQA 的模型包括 PaLM、Gemini 等。
1.3. GQA

Grouped-Query Attention (GQA) 是 MHA 和 MQA 之间的插值,通过引入多个查询头子组(少于注意力头总数),每个子组都有一个 key 和 value 头。 与 MQA 相比,随着模型大小的增加,GQA 的内存带宽和容量保持相同比例的减少。 中间数量的子组会产生比 MQA 质量更高但比 MHA 更快的插值模型。
1.4. MLA
Multi-Head Latent Attention (MLA) 实现了比 MHA 更优越的性能,并且显著降低了 KV-cache 提升推理效率。 MLA 不像 MQA 和 GQA 那样减少 KV-heads, 而是将 Key 和 Value 联合压缩到一个潜在向量中。

Low-Rank Key-Value Joint Compression

MLA 将 key 和 value 矩阵联合压缩在低秩向量中,这样可以缓存更少的项目,因为压缩维度比 MHA 中的输出投影矩阵维度要小得多。
1.5. 总结
| Attention Mechanism | KV Cache per Token (# Element) | Capability |
|---|---|---|
| Multi-Head Attention (MHA) | Strong | |
| Grouped-Query Attention (GQA) | Moderate | |
| Multi-Query Attentioin (MQA) | Weak | |
| Multi-Head Latent Attention (MLA) | Stronger |
是头数, 是每个头的维度, 是层数, 是 GQA 中的子组数, 是压缩维度。
2. 缓存与效果——工程优化
2.1. KV cache
根据 Decoder-only 的特性,每次前向完,把 KV 保留下来,用于之后的计算。
# q, k, v 当前 timestep 的 query, key, value
# K_prev, V_prev 之前所有 timestamp 的 key 和 value
for _ in range(time_step):
# ...
K = torch.cat([K_prev, k], dim=-2) # [b, h, n, d]
V = torch.cat([V_prev, v], dim=-2) # [b, h, n, d]
logits = torch.einsum("bhd, bhnd->bhn", q, K)
weights = torch.softmax(logits/math.sqrt(d), dim=-1)
outs = torch.einsum("bhn, bhnd->bhd", weights, V)
# ...
K_prev, V_prev = K, V
2.2. Flash attention
有关计算和内存的基本概念
计算(Compute)指的是 GPU 计算实际浮点运算(FLOPS)所花费的时间。 内存(Memory)指的是在 GPU 内传输张量所花费的时间。
我们的 GPU 架构中,可以把记忆体简单地分成 HBM(High Bandwidth Memory)和 SRAM(Static Random Access Memory)两个部分:
- HBM 的记忆体空间很大,但是频宽较低
- SRAM 的记忆体空间很小,但是频宽较高,用来做运算
在 GPU 跑 Attention 的流程如下:
- Load , by blocks from HBM, compute , write to HBM
- Read from HBM, compute , write to HBM
- Load and by blocks from HBM, compute , write to HBM.
- Read
由于 SRAM 又贵又小,实际上 query state 或 key state 是一小块一小块 load 进去 SRAM 的。 而矩阵 S 维度爆炸为 ,占用大量的内存,这样大量的读写导致 Attention 运算速度很慢,使得 Attention 操作成为内存绑定操作,而且会有记忆体碎片化问题。
2.2.1. FlashAttention V1
Kernel Fusion
为减少显存读取次数,若 SRAM 容量允许,多个计算步骤(矩阵乘法、softmax 归一化、masking 和 dropout)可合并在一次数据加载中完成。 这样就可以大大减少读写次数。
Backward Recomputation
在前向传播时保存归一化因子,舍弃存储中间结果 和 。 在反向传播时通过重计算得出注意力矩阵,以完成反向传播,这虽然增加了浮点运算次数,但通过减少 HBM 访问,提升了整体效率。
Softmax Tiling
Attention 当中的一个核心步骤就是 Softmax Function,受限于 SRAM 的大小关系,我们不可能一次算出所有数值的 softmax,所以需要把所有中间计算的数值存在 HBM。
tiling 的做法是,先把一块丢进去计算出 softmax,这里的 m 代表的是这一块 load 到 SRAM 的最大值——local maxima,然后就可以计算出 local softmax:
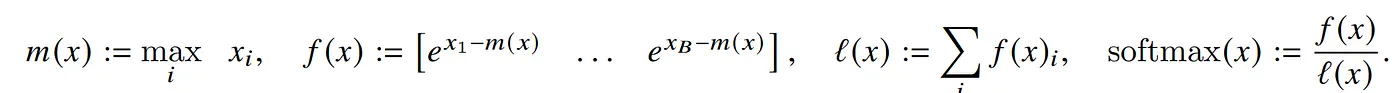
接下来第二块进来,我们把第一块的最大值和第二块的最大值取最大值,就可以得到这两块数值的最大值,然后用相同的方式计算,就可以得到这两块的 local softmax。
我们不需要把每块算出来的数值存在 HBM,我们只需要存当下的最大值 和分母加总 就可以了。
所以实际上的流程就会是这样,蓝色的区域就是 HBM,橘色虚线的区块就是 SRAM,每次运算的时候,因为 SRAM 大小有限, 所以我们只 Load 一部分的 Key state 和 value state,红色的字就是我们第一个 block 的计算,蓝色的字就是我们第二个 block 的计算。
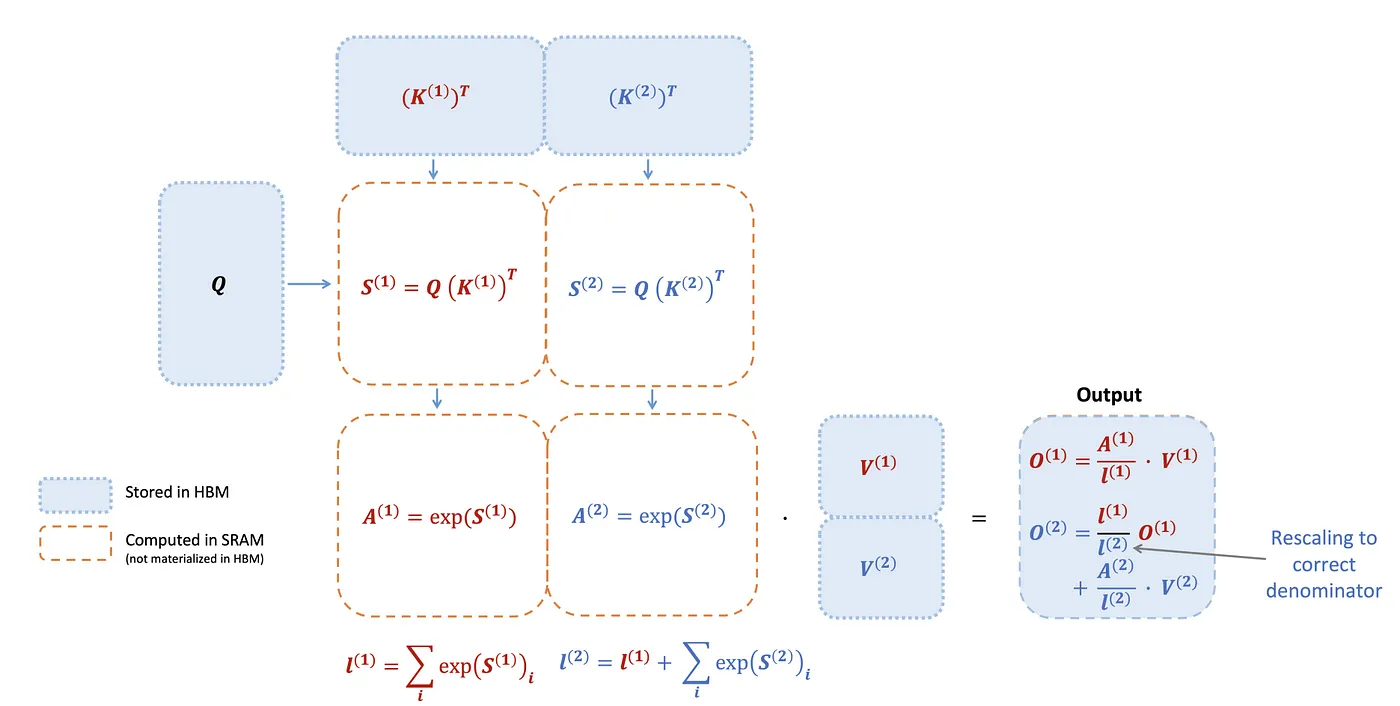
2.3. Paged attention
PagedAttention 是 vLLM 性能增强的核心。 它通过将 KV cache 缓存划分为块来解决 LLM 服务中内存管理的关键问题,从而允许在内存中非连续存储键和值。
- 每个 block 类比于虚拟内存中的一个 page。每个 block 的大小是固定的,在 vLLM 中默认大小为 16,即可装 16 个 token 的 K/V 值;
- Shared prefix: 在某些大模型中,所有请求可能都会共享一个前置信息(比如 system message),这些前置信息没有必要重复存储 KV cache;
- Beam Search、并行采样中有大量的 KV cache 是重复的。内存使用率降低 55%。
- 对物理块的引用计数进行跟踪,并实现写时复制机制。
References: